

Support `TwinFlow` via `diffusers`
Browse filesMove the weights in `TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/*` to
the root directory of the repository instead, which allows loading those
from `diffusers`, preventing `KeyError: '_class_name'` when reading the
`model_index.json` when loading via
`AutoPipelineForText2Image.from_pretrained`
- TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/LICENSE → LICENSE +0 -0
- README.md +104 -42
- TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/README.md +0 -135
- TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/model_index.json +0 -24
- model_index.json +24 -1
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/scheduler → scheduler}/scheduler_config.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/config.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/generation_config.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model-00001-of-00004.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model-00002-of-00004.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model-00003-of-00004.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model-00004-of-00004.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model.safetensors.index.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/added_tokens.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/chat_template.jinja +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/merges.txt +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/special_tokens_map.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/tokenizer_config.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/vocab.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/config.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00001-of-00008.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00002-of-00008.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00003-of-00008.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00004-of-00008.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00005-of-00008.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00006-of-00008.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00007-of-00008.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00008-of-00008.safetensors +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model.safetensors.index.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/vae → vae}/config.json +0 -0
- {TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/vae → vae}/diffusion_pytorch_model.safetensors +0 -0
TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/LICENSE → LICENSE
RENAMED
|
File without changes
|
README.md
CHANGED
|
@@ -1,73 +1,135 @@
|
|
| 1 |
---
|
| 2 |
-
base_model:
|
| 3 |
-
- Qwen/Qwen-Image
|
| 4 |
-
pipeline_tag: text-to-image
|
| 5 |
-
library_name: diffusers
|
| 6 |
license: apache-2.0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
|
| 9 |
-
<
|
|
|
|
|
|
|
| 10 |
|
| 11 |
-
|
|
|
|
| 12 |
|
| 13 |
-
|
| 14 |
-
[](https://huggingface.co/inclusionAI/TwinFlow) 
|
| 15 |
-
[](https://github.com/inclusionAI/TwinFlow) 
|
| 16 |
-
<a href="https://arxiv.org/abs/2512.05150" target="_blank"><img src="https://img.shields.io/badge/Paper-b5212f.svg?logo=arxiv" height="21px"></a>
|
| 17 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
|
| 19 |
-
</div>
|
| 20 |
|
| 21 |
-
##
|
| 22 |
|
| 23 |
-
|
|
|
|
|
|
|
|
|
|
| 24 |
|
| 25 |
-
|
| 26 |
|
| 27 |
-
|
|
|
|
|
|
|
| 28 |
|
| 29 |
-
|
| 30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
|
| 32 |
-
|
|
|
|
| 33 |
|
| 34 |
-
|
|
|
|
|
|
|
|
|
|
| 35 |
|
| 36 |
-
|
|
|
|
| 37 |
|
| 38 |
-
|
| 39 |
|
| 40 |
-
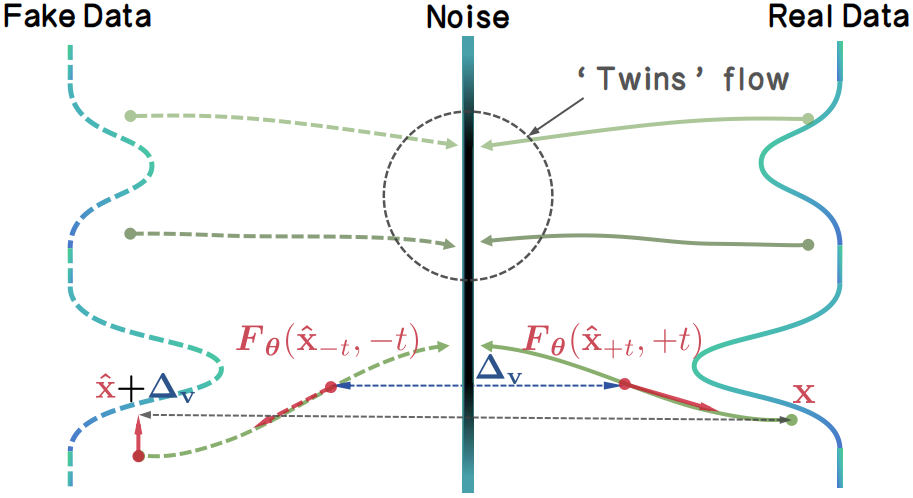
|
| 41 |
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
|
| 46 |
-
|
| 47 |
|
| 48 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 49 |
|
| 50 |
-
|
| 51 |
-
pip install git+https://github.com/huggingface/diffusers
|
| 52 |
```
|
| 53 |
|
| 54 |
-
|
| 55 |
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 59 |
|
| 60 |
## Citation
|
| 61 |
|
|
|
|
|
|
|
| 62 |
```bibtex
|
| 63 |
-
@
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
|
|
|
|
|
|
|
|
|
| 68 |
}
|
| 69 |
-
```
|
| 70 |
-
|
| 71 |
-
## Acknowledgement
|
| 72 |
-
|
| 73 |
-
TwinFlow is built upon [RCGM](https://github.com/LINs-lab/RCGM) and [UCGM](https://github.com/LINs-lab/UCGM), with much support from [InclusionAI](https://github.com/inclusionAI).
|
|
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- zh
|
| 6 |
+
library_name: diffusers
|
| 7 |
+
pipeline_tag: text-to-image
|
| 8 |
---
|
| 9 |
+
<p align="center">
|
| 10 |
+
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/qwen_image_logo.png" width="400"/>
|
| 11 |
+
<p>
|
| 12 |
+
<p align="center">
|
| 13 |
+
💜 <a href="https://chat.qwen.ai/"><b>Qwen Chat</b></a>   |   🤗 <a href="https://huggingface.co/Qwen/Qwen-Image">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/models/Qwen/Qwen-Image">ModelScope</a>   |    📑 <a href="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf">Tech Report</a>    |    📑 <a href="https://qwenlm.github.io/blog/qwen-image/">Blog</a>   
|
| 14 |
+
<br>
|
| 15 |
+
🖥️ <a href="https://huggingface.co/spaces/Qwen/qwen-image">Demo</a>   |   💬 <a href="https://github.com/QwenLM/Qwen-Image/blob/main/assets/wechat.png">WeChat (微信)</a>   |   🫨 <a href="https://discord.gg/CV4E9rpNSD">Discord</a>  
|
| 16 |
+
</p>
|
| 17 |
|
| 18 |
+
<p align="center">
|
| 19 |
+
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/merge3.jpg" width="1600"/>
|
| 20 |
+
<p>
|
| 21 |
|
| 22 |
+
## Introduction
|
| 23 |
+
We are thrilled to release **Qwen-Image**, an image generation foundation model in the Qwen series that achieves significant advances in **complex text rendering** and **precise image editing**. Experiments show strong general capabilities in both image generation and editing, with exceptional performance in text rendering, especially for Chinese.
|
| 24 |
|
| 25 |
+

|
|
|
|
|
|
|
|
|
|
| 26 |
|
| 27 |
+
## News
|
| 28 |
+
- 2025.08.04: We released the [Technical Report](https://arxiv.org/abs/2508.02324) of Qwen-Image!
|
| 29 |
+
- 2025.08.04: We released Qwen-Image weights! Check at [huggingface](https://huggingface.co/Qwen/Qwen-Image) and [Modelscope](https://modelscope.cn/models/Qwen/Qwen-Image)!
|
| 30 |
+
- 2025.08.04: We released Qwen-Image! Check our [blog](https://qwenlm.github.io/blog/qwen-image) for more details!
|
| 31 |
|
|
|
|
| 32 |
|
| 33 |
+
## Quick Start
|
| 34 |
|
| 35 |
+
Install the latest version of diffusers
|
| 36 |
+
```
|
| 37 |
+
pip install git+https://github.com/huggingface/diffusers
|
| 38 |
+
```
|
| 39 |
|
| 40 |
+
The following contains a code snippet illustrating how to use the model to generate images based on text prompts:
|
| 41 |
|
| 42 |
+
```python
|
| 43 |
+
from diffusers import DiffusionPipeline
|
| 44 |
+
import torch
|
| 45 |
|
| 46 |
+
model_name = "Qwen/Qwen-Image"
|
| 47 |
|
| 48 |
+
# Load the pipeline
|
| 49 |
+
if torch.cuda.is_available():
|
| 50 |
+
torch_dtype = torch.bfloat16
|
| 51 |
+
device = "cuda"
|
| 52 |
+
else:
|
| 53 |
+
torch_dtype = torch.float32
|
| 54 |
+
device = "cpu"
|
| 55 |
|
| 56 |
+
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
|
| 57 |
+
pipe = pipe.to(device)
|
| 58 |
|
| 59 |
+
positive_magic = {
|
| 60 |
+
"en": "Ultra HD, 4K, cinematic composition." # for english prompt,
|
| 61 |
+
"zh": "超清,4K,电影级构图" # for chinese prompt,
|
| 62 |
+
}
|
| 63 |
|
| 64 |
+
# Generate image
|
| 65 |
+
prompt = '''A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197". Ultra HD, 4K, cinematic composition'''
|
| 66 |
|
| 67 |
+
negative_prompt = " " # using an empty string if you do not have specific concept to remove
|
| 68 |
|
|
|
|
| 69 |
|
| 70 |
+
# Generate with different aspect ratios
|
| 71 |
+
aspect_ratios = {
|
| 72 |
+
"1:1": (1328, 1328),
|
| 73 |
+
"16:9": (1664, 928),
|
| 74 |
+
"9:16": (928, 1664),
|
| 75 |
+
"4:3": (1472, 1140),
|
| 76 |
+
"3:4": (1140, 1472),
|
| 77 |
+
"3:2": (1584, 1056),
|
| 78 |
+
"2:3": (1056, 1584),
|
| 79 |
+
}
|
| 80 |
|
| 81 |
+
width, height = aspect_ratios["16:9"]
|
| 82 |
|
| 83 |
+
image = pipe(
|
| 84 |
+
prompt=prompt + positive_magic["en"],
|
| 85 |
+
negative_prompt=negative_prompt,
|
| 86 |
+
width=width,
|
| 87 |
+
height=height,
|
| 88 |
+
num_inference_steps=50,
|
| 89 |
+
true_cfg_scale=4.0,
|
| 90 |
+
generator=torch.Generator(device="cuda").manual_seed(42)
|
| 91 |
+
).images[0]
|
| 92 |
|
| 93 |
+
image.save("example.png")
|
|
|
|
| 94 |
```
|
| 95 |
|
| 96 |
+
## Show Cases
|
| 97 |
|
| 98 |
+
One of its standout capabilities is high-fidelity text rendering across diverse images. Whether it’s alphabetic languages like English or logographic scripts like Chinese, Qwen-Image preserves typographic details, layout coherence, and contextual harmony with stunning accuracy. Text isn’t just overlaid—it’s seamlessly integrated into the visual fabric.
|
| 99 |
+
|
| 100 |
+

|
| 101 |
+
|
| 102 |
+
Beyond text, Qwen-Image excels at general image generation with support for a wide range of artistic styles. From photorealistic scenes to impressionist paintings, from anime aesthetics to minimalist design, the model adapts fluidly to creative prompts, making it a versatile tool for artists, designers, and storytellers.
|
| 103 |
+
|
| 104 |
+

|
| 105 |
+
|
| 106 |
+
When it comes to image editing, Qwen-Image goes far beyond simple adjustments. It enables advanced operations such as style transfer, object insertion or removal, detail enhancement, text editing within images, and even human pose manipulation—all with intuitive input and coherent output. This level of control brings professional-grade editing within reach of everyday users.
|
| 107 |
+
|
| 108 |
+

|
| 109 |
+
|
| 110 |
+
But Qwen-Image doesn’t just create or edit—it understands. It supports a suite of image understanding tasks, including object detection, semantic segmentation, depth and edge (Canny) estimation, novel view synthesis, and super-resolution. These capabilities, while technically distinct, can all be seen as specialized forms of intelligent image editing, powered by deep visual comprehension.
|
| 111 |
+
|
| 112 |
+

|
| 113 |
+
|
| 114 |
+
Together, these features make Qwen-Image not just a tool for generating pretty pictures, but a comprehensive foundation model for intelligent visual creation and manipulation—where language, layout, and imagery converge.
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
## License Agreement
|
| 118 |
+
|
| 119 |
+
Qwen-Image is licensed under Apache 2.0.
|
| 120 |
|
| 121 |
## Citation
|
| 122 |
|
| 123 |
+
We kindly encourage citation of our work if you find it useful.
|
| 124 |
+
|
| 125 |
```bibtex
|
| 126 |
+
@misc{wu2025qwenimagetechnicalreport,
|
| 127 |
+
title={Qwen-Image Technical Report},
|
| 128 |
+
author={Chenfei Wu and Jiahao Li and Jingren Zhou and Junyang Lin and Kaiyuan Gao and Kun Yan and Sheng-ming Yin and Shuai Bai and Xiao Xu and Yilei Chen and Yuxiang Chen and Zecheng Tang and Zekai Zhang and Zhengyi Wang and An Yang and Bowen Yu and Chen Cheng and Dayiheng Liu and Deqing Li and Hang Zhang and Hao Meng and Hu Wei and Jingyuan Ni and Kai Chen and Kuan Cao and Liang Peng and Lin Qu and Minggang Wu and Peng Wang and Shuting Yu and Tingkun Wen and Wensen Feng and Xiaoxiao Xu and Yi Wang and Yichang Zhang and Yongqiang Zhu and Yujia Wu and Yuxuan Cai and Zenan Liu},
|
| 129 |
+
year={2025},
|
| 130 |
+
eprint={2508.02324},
|
| 131 |
+
archivePrefix={arXiv},
|
| 132 |
+
primaryClass={cs.CV},
|
| 133 |
+
url={https://arxiv.org/abs/2508.02324},
|
| 134 |
}
|
| 135 |
+
```
|
|
|
|
|
|
|
|
|
|
|
|
TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/README.md
DELETED
|
@@ -1,135 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
language:
|
| 4 |
-
- en
|
| 5 |
-
- zh
|
| 6 |
-
library_name: diffusers
|
| 7 |
-
pipeline_tag: text-to-image
|
| 8 |
-
---
|
| 9 |
-
<p align="center">
|
| 10 |
-
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/qwen_image_logo.png" width="400"/>
|
| 11 |
-
<p>
|
| 12 |
-
<p align="center">
|
| 13 |
-
💜 <a href="https://chat.qwen.ai/"><b>Qwen Chat</b></a>   |   🤗 <a href="https://huggingface.co/Qwen/Qwen-Image">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/models/Qwen/Qwen-Image">ModelScope</a>   |    📑 <a href="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf">Tech Report</a>    |    📑 <a href="https://qwenlm.github.io/blog/qwen-image/">Blog</a>   
|
| 14 |
-
<br>
|
| 15 |
-
🖥️ <a href="https://huggingface.co/spaces/Qwen/qwen-image">Demo</a>   |   💬 <a href="https://github.com/QwenLM/Qwen-Image/blob/main/assets/wechat.png">WeChat (微信)</a>   |   🫨 <a href="https://discord.gg/CV4E9rpNSD">Discord</a>  
|
| 16 |
-
</p>
|
| 17 |
-
|
| 18 |
-
<p align="center">
|
| 19 |
-
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/merge3.jpg" width="1600"/>
|
| 20 |
-
<p>
|
| 21 |
-
|
| 22 |
-
## Introduction
|
| 23 |
-
We are thrilled to release **Qwen-Image**, an image generation foundation model in the Qwen series that achieves significant advances in **complex text rendering** and **precise image editing**. Experiments show strong general capabilities in both image generation and editing, with exceptional performance in text rendering, especially for Chinese.
|
| 24 |
-
|
| 25 |
-

|
| 26 |
-
|
| 27 |
-
## News
|
| 28 |
-
- 2025.08.04: We released the [Technical Report](https://arxiv.org/abs/2508.02324) of Qwen-Image!
|
| 29 |
-
- 2025.08.04: We released Qwen-Image weights! Check at [huggingface](https://huggingface.co/Qwen/Qwen-Image) and [Modelscope](https://modelscope.cn/models/Qwen/Qwen-Image)!
|
| 30 |
-
- 2025.08.04: We released Qwen-Image! Check our [blog](https://qwenlm.github.io/blog/qwen-image) for more details!
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
## Quick Start
|
| 34 |
-
|
| 35 |
-
Install the latest version of diffusers
|
| 36 |
-
```
|
| 37 |
-
pip install git+https://github.com/huggingface/diffusers
|
| 38 |
-
```
|
| 39 |
-
|
| 40 |
-
The following contains a code snippet illustrating how to use the model to generate images based on text prompts:
|
| 41 |
-
|
| 42 |
-
```python
|
| 43 |
-
from diffusers import DiffusionPipeline
|
| 44 |
-
import torch
|
| 45 |
-
|
| 46 |
-
model_name = "Qwen/Qwen-Image"
|
| 47 |
-
|
| 48 |
-
# Load the pipeline
|
| 49 |
-
if torch.cuda.is_available():
|
| 50 |
-
torch_dtype = torch.bfloat16
|
| 51 |
-
device = "cuda"
|
| 52 |
-
else:
|
| 53 |
-
torch_dtype = torch.float32
|
| 54 |
-
device = "cpu"
|
| 55 |
-
|
| 56 |
-
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
|
| 57 |
-
pipe = pipe.to(device)
|
| 58 |
-
|
| 59 |
-
positive_magic = {
|
| 60 |
-
"en": "Ultra HD, 4K, cinematic composition." # for english prompt,
|
| 61 |
-
"zh": "超清,4K,电影级构图" # for chinese prompt,
|
| 62 |
-
}
|
| 63 |
-
|
| 64 |
-
# Generate image
|
| 65 |
-
prompt = '''A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197". Ultra HD, 4K, cinematic composition'''
|
| 66 |
-
|
| 67 |
-
negative_prompt = " " # using an empty string if you do not have specific concept to remove
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
# Generate with different aspect ratios
|
| 71 |
-
aspect_ratios = {
|
| 72 |
-
"1:1": (1328, 1328),
|
| 73 |
-
"16:9": (1664, 928),
|
| 74 |
-
"9:16": (928, 1664),
|
| 75 |
-
"4:3": (1472, 1140),
|
| 76 |
-
"3:4": (1140, 1472),
|
| 77 |
-
"3:2": (1584, 1056),
|
| 78 |
-
"2:3": (1056, 1584),
|
| 79 |
-
}
|
| 80 |
-
|
| 81 |
-
width, height = aspect_ratios["16:9"]
|
| 82 |
-
|
| 83 |
-
image = pipe(
|
| 84 |
-
prompt=prompt + positive_magic["en"],
|
| 85 |
-
negative_prompt=negative_prompt,
|
| 86 |
-
width=width,
|
| 87 |
-
height=height,
|
| 88 |
-
num_inference_steps=50,
|
| 89 |
-
true_cfg_scale=4.0,
|
| 90 |
-
generator=torch.Generator(device="cuda").manual_seed(42)
|
| 91 |
-
).images[0]
|
| 92 |
-
|
| 93 |
-
image.save("example.png")
|
| 94 |
-
```
|
| 95 |
-
|
| 96 |
-
## Show Cases
|
| 97 |
-
|
| 98 |
-
One of its standout capabilities is high-fidelity text rendering across diverse images. Whether it’s alphabetic languages like English or logographic scripts like Chinese, Qwen-Image preserves typographic details, layout coherence, and contextual harmony with stunning accuracy. Text isn’t just overlaid—it’s seamlessly integrated into the visual fabric.
|
| 99 |
-
|
| 100 |
-

|
| 101 |
-
|
| 102 |
-
Beyond text, Qwen-Image excels at general image generation with support for a wide range of artistic styles. From photorealistic scenes to impressionist paintings, from anime aesthetics to minimalist design, the model adapts fluidly to creative prompts, making it a versatile tool for artists, designers, and storytellers.
|
| 103 |
-
|
| 104 |
-

|
| 105 |
-
|
| 106 |
-
When it comes to image editing, Qwen-Image goes far beyond simple adjustments. It enables advanced operations such as style transfer, object insertion or removal, detail enhancement, text editing within images, and even human pose manipulation—all with intuitive input and coherent output. This level of control brings professional-grade editing within reach of everyday users.
|
| 107 |
-
|
| 108 |
-

|
| 109 |
-
|
| 110 |
-
But Qwen-Image doesn’t just create or edit—it understands. It supports a suite of image understanding tasks, including object detection, semantic segmentation, depth and edge (Canny) estimation, novel view synthesis, and super-resolution. These capabilities, while technically distinct, can all be seen as specialized forms of intelligent image editing, powered by deep visual comprehension.
|
| 111 |
-
|
| 112 |
-

|
| 113 |
-
|
| 114 |
-
Together, these features make Qwen-Image not just a tool for generating pretty pictures, but a comprehensive foundation model for intelligent visual creation and manipulation—where language, layout, and imagery converge.
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
## License Agreement
|
| 118 |
-
|
| 119 |
-
Qwen-Image is licensed under Apache 2.0.
|
| 120 |
-
|
| 121 |
-
## Citation
|
| 122 |
-
|
| 123 |
-
We kindly encourage citation of our work if you find it useful.
|
| 124 |
-
|
| 125 |
-
```bibtex
|
| 126 |
-
@misc{wu2025qwenimagetechnicalreport,
|
| 127 |
-
title={Qwen-Image Technical Report},
|
| 128 |
-
author={Chenfei Wu and Jiahao Li and Jingren Zhou and Junyang Lin and Kaiyuan Gao and Kun Yan and Sheng-ming Yin and Shuai Bai and Xiao Xu and Yilei Chen and Yuxiang Chen and Zecheng Tang and Zekai Zhang and Zhengyi Wang and An Yang and Bowen Yu and Chen Cheng and Dayiheng Liu and Deqing Li and Hang Zhang and Hao Meng and Hu Wei and Jingyuan Ni and Kai Chen and Kuan Cao and Liang Peng and Lin Qu and Minggang Wu and Peng Wang and Shuting Yu and Tingkun Wen and Wensen Feng and Xiaoxiao Xu and Yi Wang and Yichang Zhang and Yongqiang Zhu and Yujia Wu and Yuxuan Cai and Zenan Liu},
|
| 129 |
-
year={2025},
|
| 130 |
-
eprint={2508.02324},
|
| 131 |
-
archivePrefix={arXiv},
|
| 132 |
-
primaryClass={cs.CV},
|
| 133 |
-
url={https://arxiv.org/abs/2508.02324},
|
| 134 |
-
}
|
| 135 |
-
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/model_index.json
DELETED
|
@@ -1,24 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"_class_name": "QwenImagePipeline",
|
| 3 |
-
"_diffusers_version": "0.34.0.dev0",
|
| 4 |
-
"scheduler": [
|
| 5 |
-
"diffusers",
|
| 6 |
-
"FlowMatchEulerDiscreteScheduler"
|
| 7 |
-
],
|
| 8 |
-
"text_encoder": [
|
| 9 |
-
"transformers",
|
| 10 |
-
"Qwen2_5_VLForConditionalGeneration"
|
| 11 |
-
],
|
| 12 |
-
"tokenizer": [
|
| 13 |
-
"transformers",
|
| 14 |
-
"Qwen2Tokenizer"
|
| 15 |
-
],
|
| 16 |
-
"transformer": [
|
| 17 |
-
"diffusers",
|
| 18 |
-
"QwenImageTransformer2DModel"
|
| 19 |
-
],
|
| 20 |
-
"vae": [
|
| 21 |
-
"diffusers",
|
| 22 |
-
"AutoencoderKLQwenImage"
|
| 23 |
-
]
|
| 24 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
model_index.json
CHANGED
|
@@ -1 +1,24 @@
|
|
| 1 |
-
{
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "QwenImagePipeline",
|
| 3 |
+
"_diffusers_version": "0.34.0.dev0",
|
| 4 |
+
"scheduler": [
|
| 5 |
+
"diffusers",
|
| 6 |
+
"FlowMatchEulerDiscreteScheduler"
|
| 7 |
+
],
|
| 8 |
+
"text_encoder": [
|
| 9 |
+
"transformers",
|
| 10 |
+
"Qwen2_5_VLForConditionalGeneration"
|
| 11 |
+
],
|
| 12 |
+
"tokenizer": [
|
| 13 |
+
"transformers",
|
| 14 |
+
"Qwen2Tokenizer"
|
| 15 |
+
],
|
| 16 |
+
"transformer": [
|
| 17 |
+
"diffusers",
|
| 18 |
+
"QwenImageTransformer2DModel"
|
| 19 |
+
],
|
| 20 |
+
"vae": [
|
| 21 |
+
"diffusers",
|
| 22 |
+
"AutoencoderKLQwenImage"
|
| 23 |
+
]
|
| 24 |
+
}
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/scheduler → scheduler}/scheduler_config.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/config.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/generation_config.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model-00001-of-00004.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model-00002-of-00004.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model-00003-of-00004.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model-00004-of-00004.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/text_encoder → text_encoder}/model.safetensors.index.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/added_tokens.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/chat_template.jinja
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/merges.txt
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/special_tokens_map.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/tokenizer_config.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/tokenizer → tokenizer}/vocab.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/config.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00001-of-00008.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00002-of-00008.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00003-of-00008.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00004-of-00008.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00005-of-00008.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00006-of-00008.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00007-of-00008.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model-00008-of-00008.safetensors
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/transformer → transformer}/diffusion_pytorch_model.safetensors.index.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/vae → vae}/config.json
RENAMED
|
File without changes
|
{TwinFlow-Qwen-Image-v1.0/TwinFlow-Qwen-Image/vae → vae}/diffusion_pytorch_model.safetensors
RENAMED
|
File without changes
|