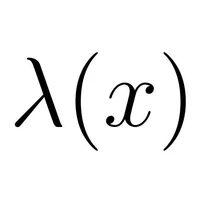AutoResearch-RL: Perpetual Self-Evaluating Reinforcement Learning Agents for Autonomous Neural Architecture Discovery
We present AutoResearch-RL, a framework in which a reinforcement learning agent conducts open-ended neural architecture and hyperparameter research without human supervision, running perpetually until a termination oracle signals convergence or resource exhaustion. At each step the agent proposes a code modification to a target training script, executes it under a fixed wall clock time budget, observes a scalar reward derived from validation bits-per-byte (val-bpb), and updates its policy via Proximal Policy Optimisation (PPO). The key design insight is the separation of three concerns: (i) a frozen environment (data pipeline, evaluation protocol, and constants) that guarantees fair cross-experiment comparison; (ii) a mutable target file (train.py) that represents the agent's editable state; and (iii) a meta-learner (the RL agent itself) that accumulates a growing trajectory of experiment outcomes and uses them to inform subsequent proposals. We formalise this as a Markov Decision Process, derive convergence guarantees under mild assumptions, and demonstrate empirically on a single GPU nanochat pretraining benchmark that AutoResearch-RL discovers configurations that match or exceed hand-tuned baselines after approximately 300 overnight iterations, with no human in the loop.