
Search is not available for this dataset
image
imagewidth (px) 605
5.63k
|
|---|
YAML Metadata
Warning:
empty or missing yaml metadata in repo card
(https://huggingface.co/docs/hub/datasets-cards)
Overview
We provides a clean, reproducible implementation of VL-RouterBench, a benchmark and toolkit for routing across a pool of Vision–Language Models (VLMs) under both performance and performance–cost objectives.
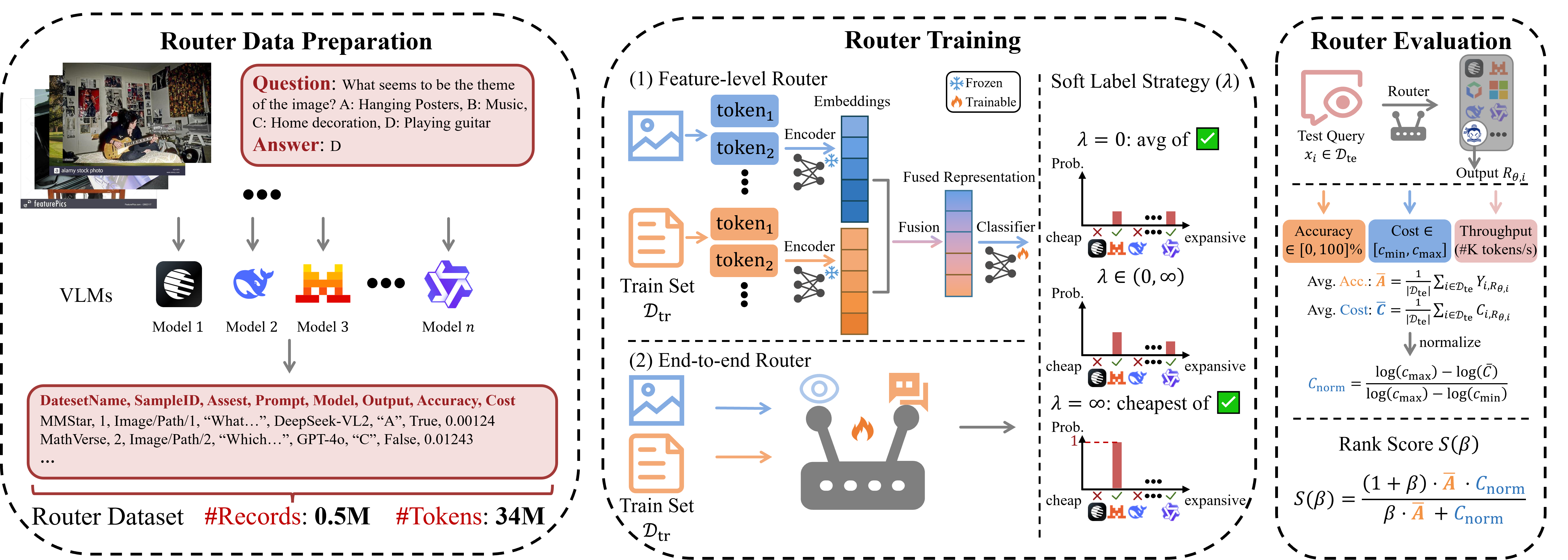
📦 Data Preparation
VL-RouterBench converts VLMEvalKit outputs into a unified routing benchmark.
To make data setup easier, we provide a pre-packaged archive vlm_router_data.tar.gz that contains everything needed to run the pipeline. You can download it from any of the following channels and extract it under the repo root:
- Google Drive: vlm_router_data.tar.gz
- Baidu Netdisk: vlm_router_data.tar.gz (code: xb1s)
- Hugging Face: vlm_router_data.tar.gz
After downloading, extract it as:
tar -xzf vlm_router_data.tar.gz
By default, the pipeline expects the following directories (relative to repo root):
vlm_router_data/
VLMEvalKit_evaluation/ # required (for is_correct / evaluation)
VLMEvalKit_inference/ # required for accurate output-token counting (Step 2)
TSV_images/ # optional (for TSV-packed image datasets)
Notes:
VLMEvalKit_evaluation/is used by Step 1 & 4 (contains correctness signals).VLMEvalKit_inference/is used by Step 2 (extract real model outputs to count output tokens).TSV_images/is used by routers for training and inference to make routing decisions.
📝 Citation
If you find this benchmark useful, please cite:
@misc{huang2025vlrouterbenchbenchmarkvisionlanguagemodel,
title={VL-RouterBench: A Benchmark for Vision-Language Model Routing},
author={Zhehao Huang and Baijiong Lin and Jingyuan Zhang and Jingying Wang and Yuhang Liu and Ning Lu and Tao Li and Xiaolin Huang},
year={2025},
eprint={2512.23562},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2512.23562},
}
- Downloads last month
- 1