
Atlas Export
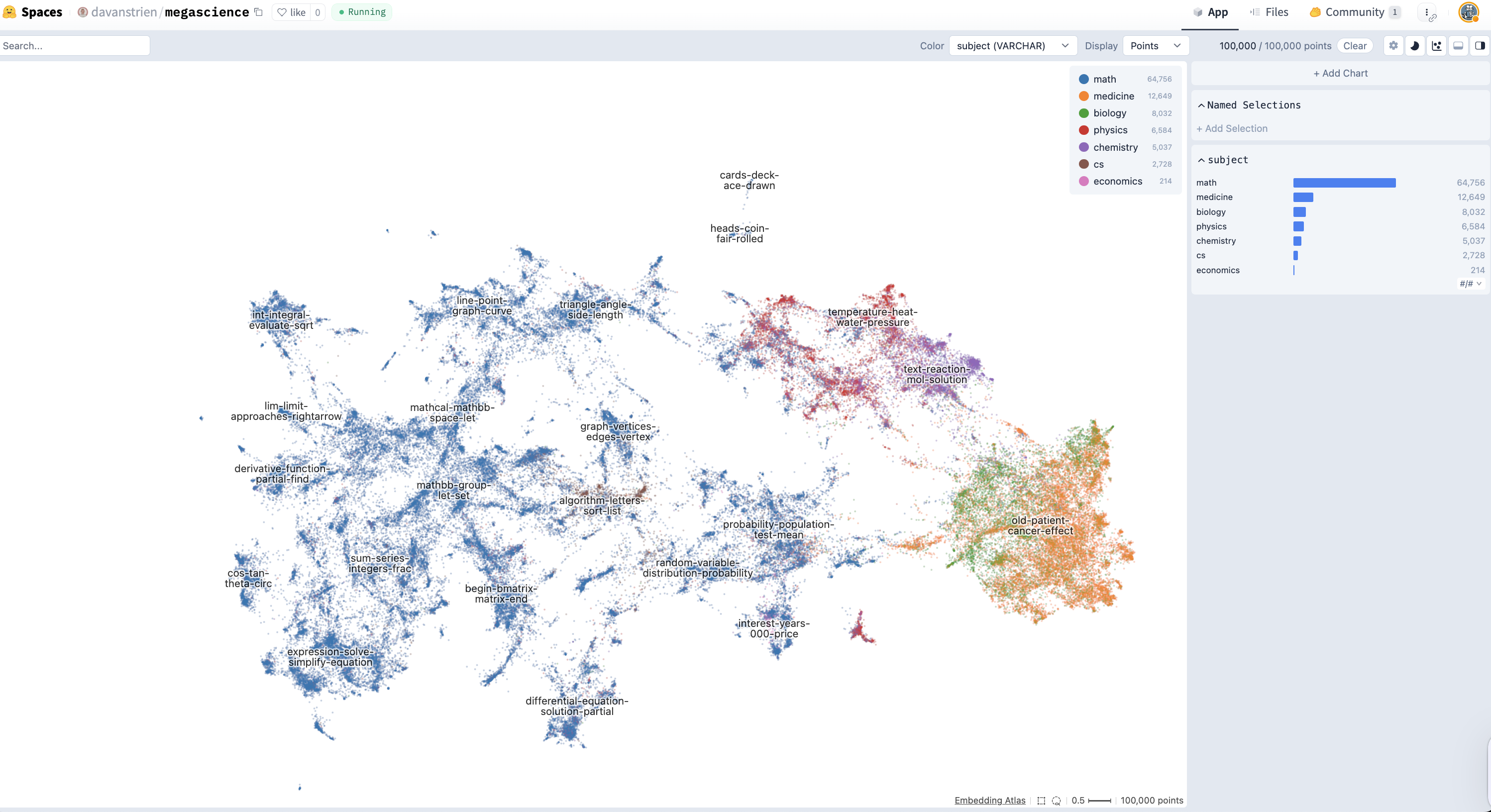
Embedding Atlas is an open-source library from Apple for creating interactive, browser-based visualizations of embedding spaces. It renders millions of data points with WebGPU acceleration, supports real-time search and filtering, and automatically generates cluster labels — all running as a static site with no backend.
These scripts wrap Embedding Atlas to make it easy to go from a HuggingFace dataset to a deployed visualization in a single command. See arxiv-cs-atlas for a live example (215K arXiv CS papers).
Scripts
This repo contains two scripts:
| Script | Description | Best for |
|---|---|---|
atlas-export.py |
All-in-one: embeds data into the Space | Small/medium datasets (<10GB) |
atlas-export-remote.py |
Splits data into a separate HF dataset repo | Large datasets (10GB+), images |
Why remote?
atlas-export-remote.py stores the parquet data in a separate HF dataset repository and the viewer in a lightweight Space. The viewer loads data on-demand via HTTP range requests — no storage limits on the Space side. This uses embedding-atlas >= 0.18.0's native --export-metadata for clean remote data loading.
Quick Start
Basic (data embedded in Space)
uv run atlas-export.py stanfordnlp/imdb --space-name my-imdb-viz
Remote data (recommended for larger datasets)
uv run atlas-export-remote.py stanfordnlp/imdb \
--space-name my-imdb-viz \
--data-repo my-imdb-data
Examples
Text Datasets
# Custom embedding model with sampling
uv run atlas-export-remote.py wikipedia \
--space-name wiki-viz \
--data-repo wiki-atlas-data \
--model nomic-ai/nomic-embed-text-v1.5 \
--text-column text \
--sample 50000
Image Datasets
# Visualize image datasets with CLIP
uv run atlas-export-remote.py food101 \
--space-name food-atlas \
--data-repo food-atlas-data \
--image-column image \
--text-column label \
--sample 5000
Pre-computed Embeddings
# If you already have embeddings in your dataset
uv run atlas-export.py my-dataset-with-embeddings \
--space-name my-viz \
--no-compute-embeddings \
--x-column umap_x \
--y-column umap_y
From an Existing Export
# Use an atlas export ZIP you already have
uv run atlas-export-remote.py \
--from-export atlas_export.zip \
--space-name my-viz \
--data-repo my-data
Sharded Datasets (Glob)
# Use a glob pattern to combine multiple parquet shards
hf jobs uv run --flavor a10g-small -s HF_TOKEN \
https://huggingface.co/datasets/uv-scripts/build-atlas/raw/main/atlas-export-remote.py \
--glob "hf://datasets/HuggingFaceFW/finephrase/faq/*.parquet" \
--glob-max-shards 10 \
--space-name finephrase-atlas --data-repo finephrase-data \
--text-column text --sample 50000
Multiple Parquet URLs
# Pass several parquet URLs directly as inputs
hf jobs uv run --flavor t4-small -s HF_TOKEN \
https://huggingface.co/datasets/uv-scripts/build-atlas/raw/main/atlas-export-remote.py \
https://huggingface.co/datasets/my-org/my-data/resolve/main/shard-0.parquet \
https://huggingface.co/datasets/my-org/my-data/resolve/main/shard-1.parquet \
https://huggingface.co/datasets/my-org/my-data/resolve/main/shard-2.parquet \
--space-name my-atlas --data-repo my-data \
--text-column text --sample 50000
Lance Format Datasets
# Lance datasets work out of the box (pylance is included)
hf jobs uv run --flavor a100-large -s HF_TOKEN \
https://huggingface.co/datasets/uv-scripts/build-atlas/raw/main/atlas-export-remote.py \
librarian-bots/arxiv-cs-papers-lance \
--space-name arxiv-atlas --data-repo arxiv-data \
--text-column abstract
GPU Acceleration (HF Jobs)
# Run on HF Jobs with GPU — the recommended way for large datasets
hf jobs uv run --flavor t4-small -s HF_TOKEN \
https://huggingface.co/datasets/uv-scripts/build-atlas/raw/main/atlas-export-remote.py \
stanfordnlp/imdb \
--space-name imdb-viz \
--data-repo imdb-atlas-data \
--sample 10000
# With a bigger GPU for faster processing
hf jobs uv run --flavor a10g-large -s HF_TOKEN \
https://huggingface.co/datasets/uv-scripts/build-atlas/raw/main/atlas-export-remote.py \
your-dataset \
--space-name your-atlas \
--data-repo your-atlas-data \
--text-column output \
--sample 50000
Available GPU flavors: t4-small, t4-medium, l4x1, a10g-small, a10g-large, a100-large.
For large datasets, add --timeout 7200 (2 hours) to the hf jobs command.
Key Options
atlas-export.py
| Option | Description | Default |
|---|---|---|
dataset_id |
HuggingFace dataset to visualize | Required |
--space-name |
Name for your Space | Required |
--model |
Embedding model to use | Auto-selected |
--text-column |
Column containing text | "text" |
--image-column |
Column containing images | None |
--sample |
Number of samples to visualize | All |
--batch-size |
Batch size for embedding generation | 32 (text), 16 (images) |
--split |
Dataset split to use | "train" |
atlas-export-remote.py
| Option | Description | Default |
|---|---|---|
inputs |
Dataset ID(s) or parquet URL(s) — positional, supports multiple | Required* |
--space-name |
Name for your Space | Required |
--data-repo |
Name for the HF dataset repo (stores parquet) | Required |
--glob |
HF glob pattern for parquet shards | None |
--glob-max-shards |
Randomly sample N shards from glob matches | All |
--model |
Embedding model to use | Auto-selected |
--text-column |
Column containing text | "text" |
--image-column |
Column containing images | None |
--sample |
Number of samples to visualize | All |
--split |
Dataset split to use | "train" |
--trust-remote-code |
Trust remote code in datasets/models | False |
--from-export |
Use an existing atlas export ZIP | None |
--organization |
HF org for repos (default: your username) | None |
--private |
Make both Space and dataset private | False |
--private-space |
Make only the Space private | False |
--private-data |
Make only the dataset private | False |
--hf-token |
Explicit HF token (or set HF_TOKEN env) | Auto |
--output-dir |
Local output directory | Temp dir |
--local-only |
Prepare locally without deploying | False |
*Either inputs, --glob, or --from-export is required.
Run either script without arguments to see all options.
How It Works
atlas-export.py
- Loads dataset from HuggingFace Hub
- Generates embeddings (or uses pre-computed)
- Creates static web app with embedded data
- Deploys to HF Space
atlas-export-remote.py
- Loads dataset and generates embeddings
- Exports viewer with
--export-metadatapointing to the remote parquet URL - Uploads parquet to a HF dataset repo
- Deploys the lightweight viewer (~100MB) to a HF Space
- The viewer fetches data on-demand via HTTP range requests
Tips
- Re-running with the same
--space-name/--data-repoupdates in place (no need to delete first) - Lance format is supported out of the box —
pylanceis bundled as a dependency - Source datasets are automatically linked in the Space metadata
- More shards = more RAM — use
a10g-largeora100-largefor many shards - Keep
--glob-max-shardsreasonable (5-30) to avoid OOM on smaller GPU flavors
Live Examples
- arxiv-cs-atlas — 215K arXiv CS papers (lance format)
- finephrase-faq-atlas — 50K FAQ entries (glob pattern)
Credits
Built on Embedding Atlas by Apple (>= 0.18.0 for remote data support). See the documentation for more details.
Part of the UV Scripts collection 🚀
- Downloads last month
- 62